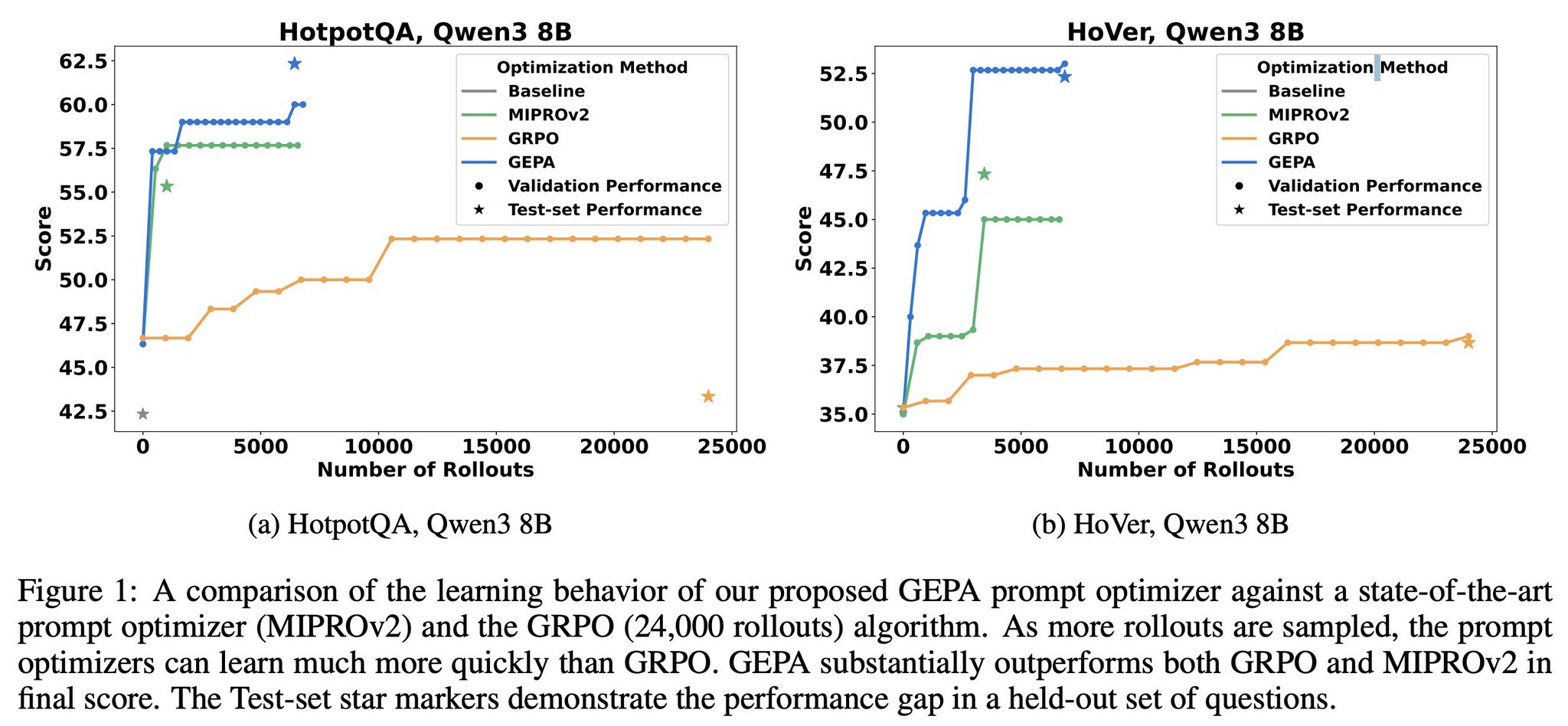
this seems really important: it is totally plausible that a model could get IMO gold without *any* reinforcement learning, given a perfectly-crafted prompt we just don't know, and lack tools to efficiently search through prompt space. glad to see at least someone is trying
Models achieving gold without reinforcement learning through prompt engineering
By
–