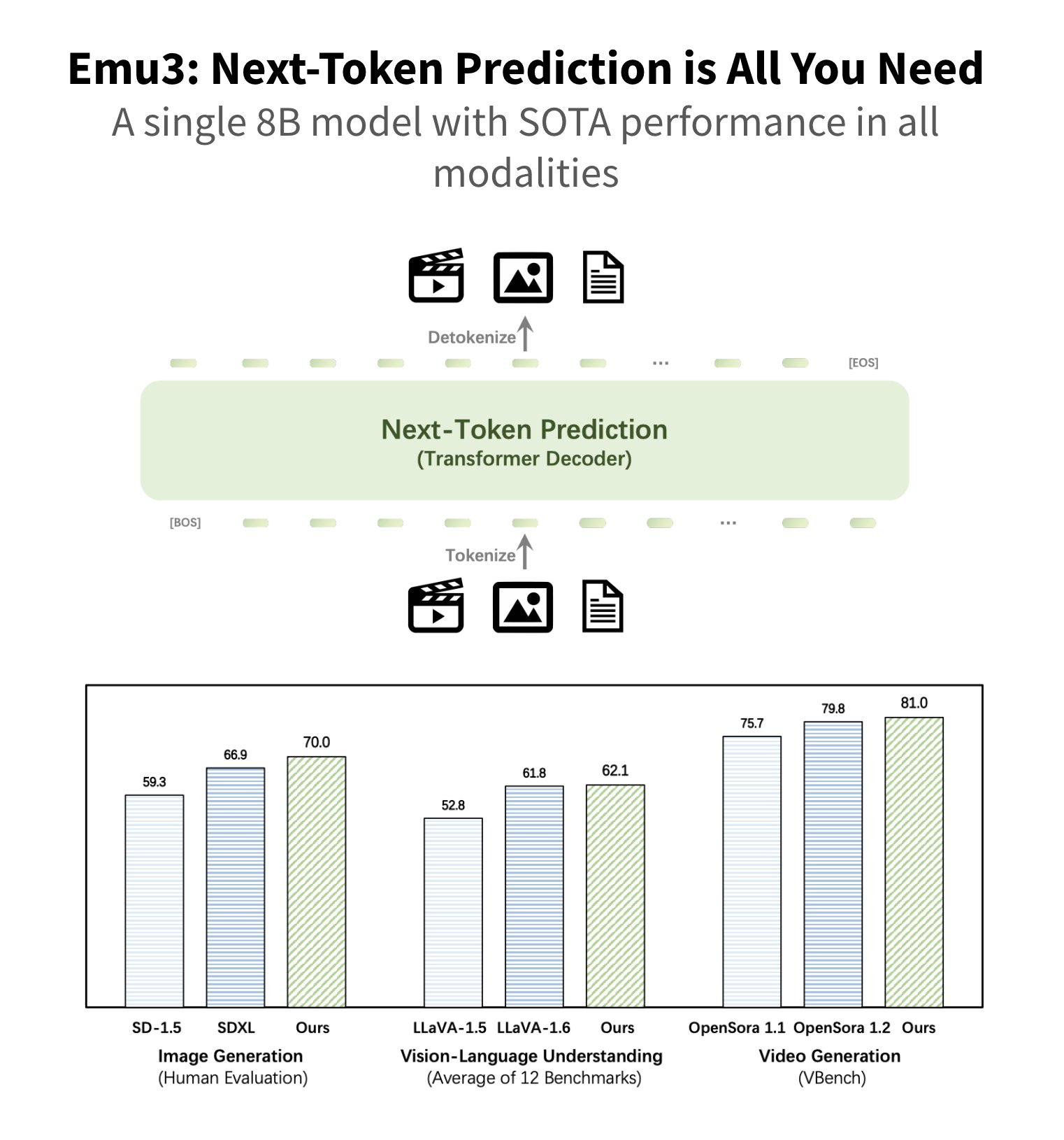
> Emu3: Next-token prediction conquers multimodal tasks This is the most important research in months: we’re now very close to having a single architecture to handle all modalities. The folks at BAAI just released Emu3, a single model that handles text, images, and videos all
Emu3: single model handles text, images, and videos
By
–