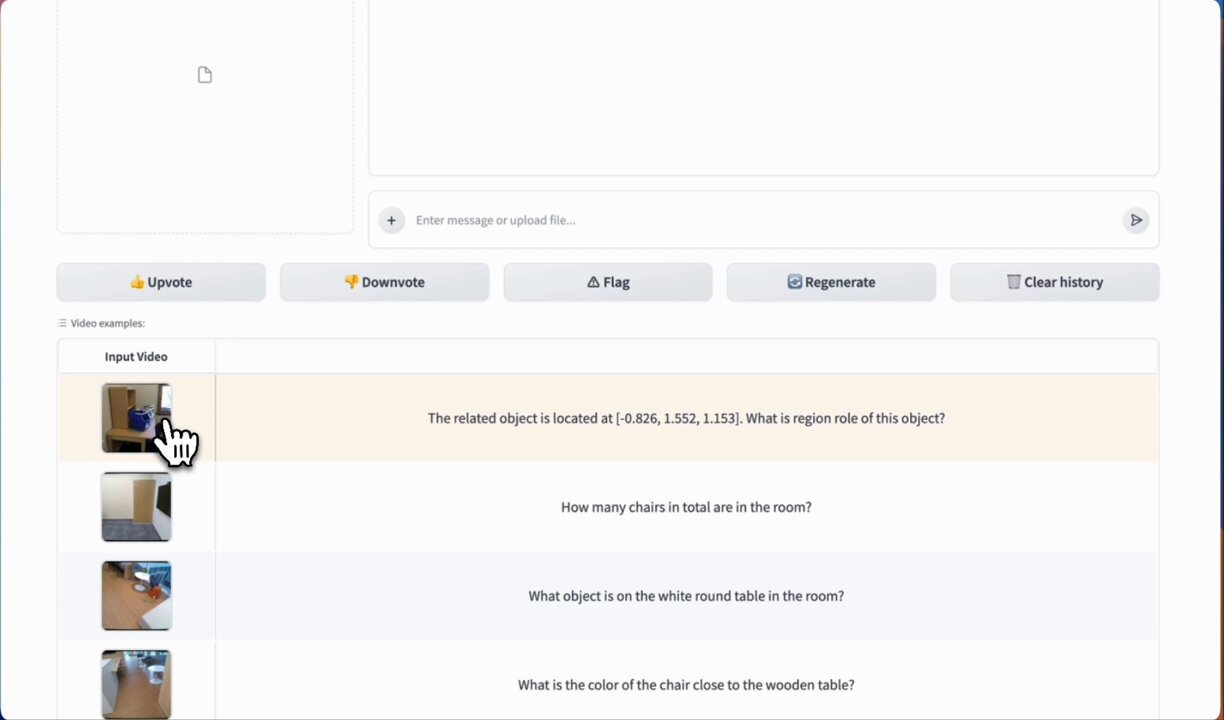
LLaVA-3D
— AK (@_akhaliq) 27 septembre 2024
A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness
Recent advancements in Large Multimodal Models (LMMs) have greatly enhanced their proficiency in 2D visual understanding tasks, enabling them to effectively process and understand images and videos.… pic.twitter.com/pbyiLnBhr6
LLaVA-3D A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness Recent advancements in Large Multimodal Models (LMMs) have greatly enhanced their proficiency in 2D visual understanding tasks, enabling them to effectively process and understand images and videos.