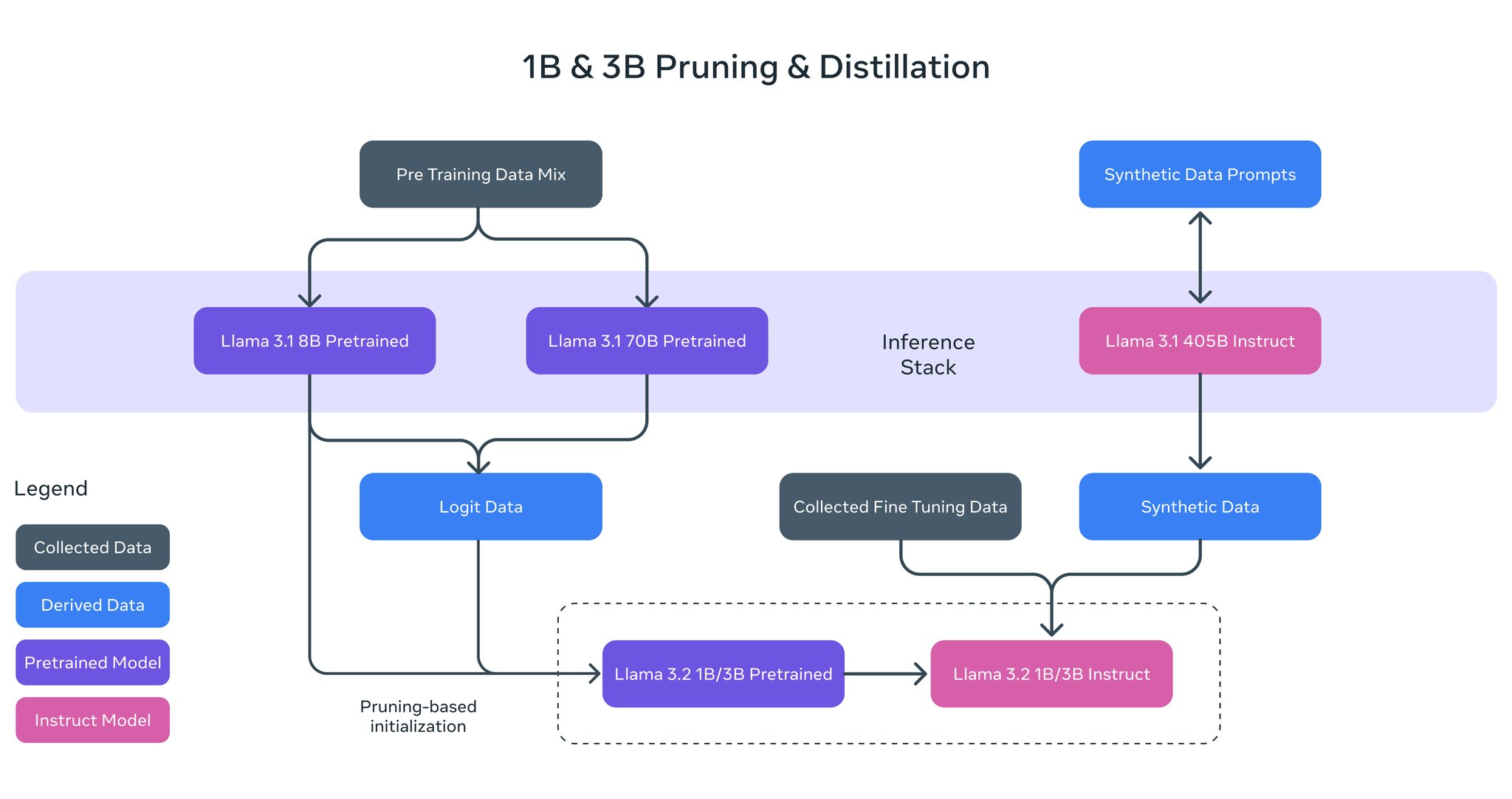
These lightweight Llama models were pretrained on up to 9 trillion tokens. One of the keys for Llama 1B & 3B however was using pruning & distillation to build smaller and more performant models informed by powerful teacher models. Pruning enabled us to reduce the size of extant
Llama Lightweight Models: Pruning and Distillation Techniques
By
–