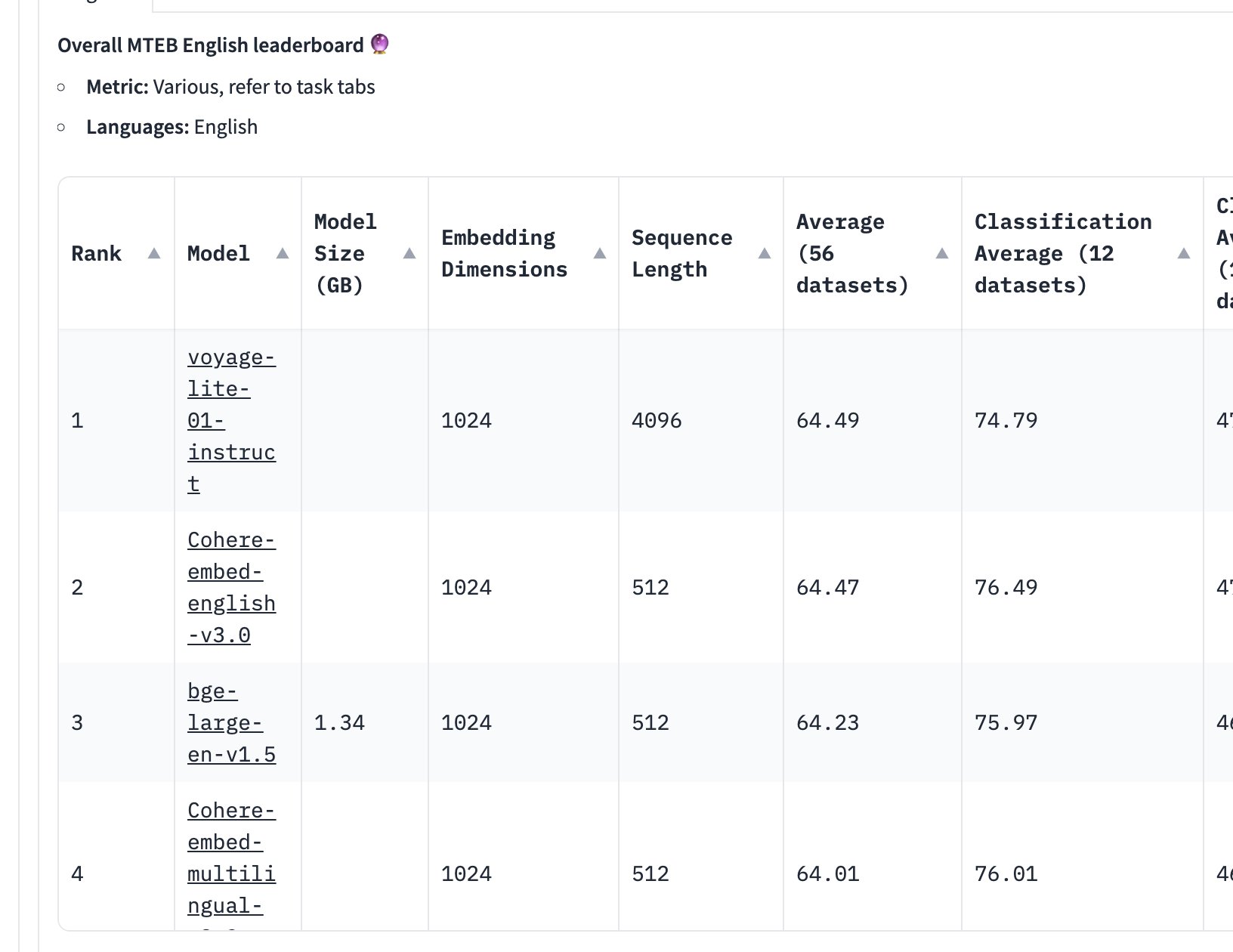
why aren't we training massive embedders? some guesses:
– contrastive loss isn't the right loss function for embeddings
– not enough good paired data
– unclear what the use case is (retrieval? clustering? classification?)
– no principled scaling laws
– diminishing returns
Why Aren’t We Training Massive Embedders?
By
–