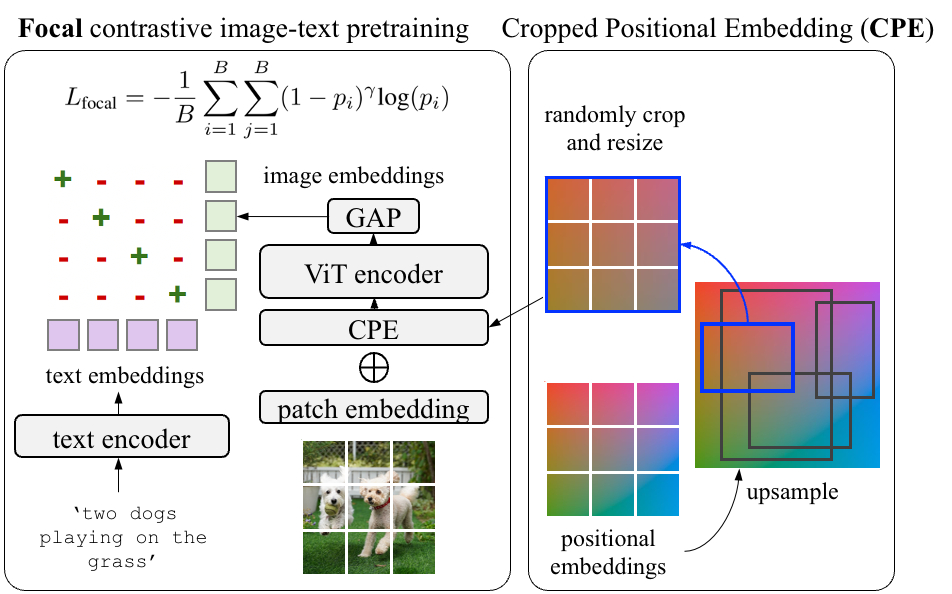
Check out RO-ViT, a simple method to pre-train vision transformers in a region-aware manner (using a novel technique called “cropped positional embeddings”) to improve open-vocabulary detection. Learn more and grab the code at https://
goo.gle/3YB7cFC.
RO-ViT: Region-Aware Vision Transformer Pre-Training Method
By
–